Let's All Dance: Enhancing Amateur Dance Motions

Let's All Dance: Enhancing Amateur Dance Motions
Qiu Zhou, Manyi Li, Qiong Zeng, Andreas Aristidou, Xiaojing Zhang, Lin Chen, Changhe Tu
Computational Visual Media, Vol.9, No.3, September 2023
In this paper, we present a deep model that enhances professionalism to amateur dance movements, allowing the movement quality to be improved in both the spatial and temporal domains. We illustrate the effectiveness of our method on real amateur and artificially generated dance movements. We also demonstrate that our method can synchronize 3D dance motions with any reference audio under non-uniform and irregular misalignment.
[DOI] [paper] [supplementary materials] [code] [data] [bibtex]
Abstract
Professional dancing is characterized by high impulsiveness, elegance, and aesthetic beauty. In order to reach the desired professionalism, it requires years of long and exhausting practice, good physical condition, musicality, but also, a good understanding of the choreography. Capturing dance motions and transferring them into digital avatars is commonly used in the film and entertainment industries. However, so far, access to high-quality dance data is very limited, mainly due to the many practical difficulties in motion capturing the movement of dancers, which makes it prohibitive for large-scale acquisitions. In this paper, we present a model that enhances professionalism to amateur dance movements, allowing the movement quality to be improved in both the spatial and temporal domains. The model consists of a dance-to-music alignment stage responsible for learning the optimal temporal alignment path between the dance and music, and a dance-enhancement stage that injects features of professionalism in both the spatial and temporal domains. To learn a homogeneous distribution and credible mapping between the heterogeneous professional and amateur datasets, we generate amateur data from professional dances taken from the AIST++ dataset. We demonstrate the effectiveness of our method by comparing it with two baseline motion transfer methods via thorough qualitative visual controls, quantitative metrics, and a perceptual study. We also provide temporal and spatial module analysis to examine the mechanisms and necessity of key components in our framework.
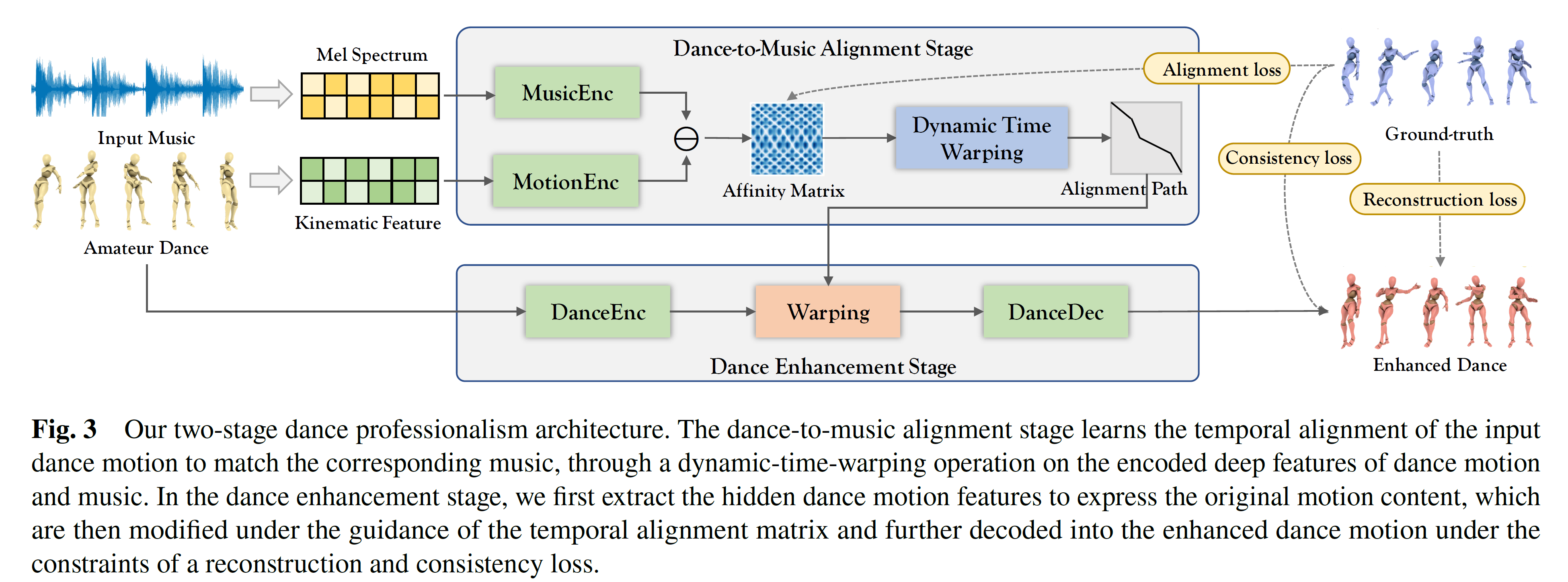
The main contributions of this work include:
- We introduce the concept of enhancing professionalism in dance movements; we give a first definition of what dance professionalism is, and how a professional dance can be distinguished from an amateur.
- We design a novel two-stage deep learning framework that extracts meaningful features from motion inputs, in terms of the newly defined professionalism criteria, to improve the quality of dance motions. It integrates a reconstruction loss, to preserve the original content of the dance, and a consistency loss, to maintain the temporal coherency of the reconstructed motion.
- We propose a novel model designed to synchronize 3D dance motions with a reference audio under non-uniform and irregular misalignment.
- We present thorough evaluations, and an ablation study to examine the efficiency and necessity of our method.
Acknowlegments
This research was supported by the grants of NSFC (No. 62072284), the grant of Natural Science Foundation of Shandong Province (No. ZR2021MF102), the Special Project of Shandong Province for Software Engineering (11480004042015), and internal funds from the University of Cyprus. The authors would like to thank Anastasios Yiannakidis (University of Cyprus) for capturing the amateur dances, Mingyi Shi (Hongkong University) for discussions, and the volunteers for attending the perceptual studies. The authors would also like to thank the anonymous reviewers and the editors for their fruitful comments and suggestions.


© 2025 Andreas Aristidou